GPU Nodes
THIS SITE IS DEPRECATED
We have transitioned to another service and are no longer actively updating this site.
Refer to our new documentation at: hpcdocs.hpc.arizona.edu
Cluster Information
Puma
Puma has a different arrangement for GPU nodes than Ocelote and ElGato. Whereas the older clusters have one GPU per node, Puma has four. This has a financial advantage for providing GPU's with lower overall cost, and a technical advantage of allowing jobs that can use multiple GPU's to run faster than spanning multiple nodes. This capability comes from using a newer operating system.
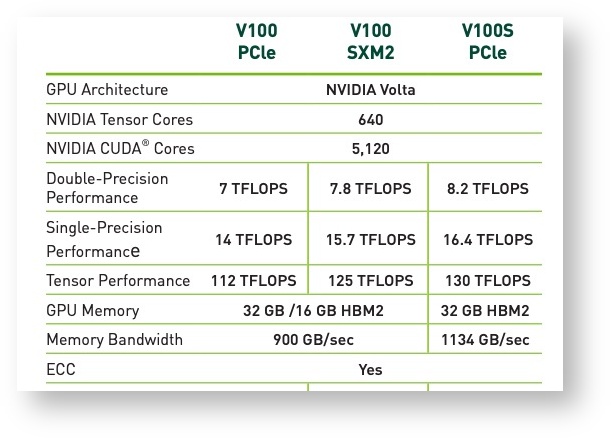
Each node has four Nvidia V100S model GPUs. They are provisioned with 32GB memory compared to 16GB on the P100's.
Ocelote
Ocelote has 46 compute nodes with Nvidia P100 GPUs that are available to researchers on campus. The limitation is a maximum of 10 concurrent jobs. Previously, one node with a V100 was available, but it has since been replaced with a P100. Tasks which require multiple GPUs must either request multiple nodes on Ocelote, or use Puma's GPU nodes.

Cuda Modules
Nvidia Nsight Compute (the interactive kernel profiler) is not available. In response to a security alert (CVE-2018-6260) this capability is only available with root authority which users do not have.
The latest Cuda module available on the system is 11.8, with several older versions also available.The Cuda driver version can be queried with the nvidia-smi command. To see the modules available, in an interactive session simply run:
$ module avail cuda -------------------- /opt/ohpc/pub/moduledeps/gnu8-openmpi3 --------------------- cp2k-cuda/7.1.0 --------------------------- /opt/ohpc/pub/modulefiles --------------------------- cuda11-dnn/8.0.2 cuda11-sdk/20.7 cuda11/11.0 cuda11-dnn/8.1.1 cuda11-sdk/21.3 cuda11/11.2 cuda11-dnn/8.9.2 (D) cuda11-sdk/22.11 (D) cuda11/11.8 (D)
OpenACC
The OpenACC API is a collection of compiler directives and runtime routines that allow you to specify loops and regions of code in standard C, C++, and Fortran that you can offload from a host CPU to the GPU.
We provide two methods of support for OpenACC
- We support OpenACC in the PGI Compiler. The PGI implementation of OpenACC is considered the best implementation.
"module load pgi" on Ocelote. If you are on a GPU node from an interactive session you can run "pgaccelinfo" to test functionality. Remember that the login nodes do not have GPUs or software installed.
A useful getting-started guide written by Nvidia is available here: https://www.pgroup.com/doc/openacc17_gs.pdf - We support OpenACC in the GCC Compiler 6.1 which is automatically loaded as a module when you log into Ocelote. Verify with "module list".
The GCC 6 release includes a much improved implementation of the OpenACC 2.0a specification.
A useful quick reference guide is available from: https://gcc.gnu.org/wiki/OpenACC#Quick_Reference_Guide
Applications
Many applications have been optimized to run faster on GPU's. These include:
| Application | Information | Access |
|---|---|---|
| NAMD | Installed as a module | $ module load namd |
| VASP | A restricted license version is installed; only available to licensed users | $ module load vasp |
| GROMACS | Installed as a module | $ module load gromacs |
| LAMMPS | Installed as a module | $ module load lammps |
| ABAQUS | Installed as a module and available as an application through Open OnDemand | $ module load abaqus |
| GAUSSIAN | Installed as a module. See these notes. | $ module load gaussian/g16 |
| MATLAB | Installed as a module and available as an application through Open OnDemand. Review the GPU Coder on their website | $ module load matlab |
| ANSYS Fluent | Installed as a module and available as an application through Open OnDemand | $ module load ansys |
| RELION | Available as a Singularity container or as a module. | $ module load relion |
| ML and DL Frameworks | See the section below. |
Python ML/DL including Nvidia RAPIDS
The minimum version of Python that is supported is 3.6:
| Framework | Details |
|---|---|
| numba | RAPIDS: numba is for Cuda programming |
| cuml | RAPIDS: Cuda Machine Learning has many ML algorithms like K-means, PCA and SVM |
| cudf | RAPIDS: Cuda Dataframes supports loading and manipulating datasets |
| tensorflow | TensorFlow is an open source software library for numerical computation using data flow graphs. |
| torch | PyTorch supports tensor computation and deep neural networks |
| caffe2 | A deep learning framework |
| tensorrt | Inference server for deep learning |
| tensorboard | Visualization tool for machine learning |