Containers
THIS SITE IS DEPRECATED
We have transitioned to another service and are no longer actively updating this site.
Refer to our new documentation at: hpcdocs.hpc.arizona.edu
Singularity/Apptainer update
During the October 26, 2022 maintenance window, Singularity was removed and replaced with Apptainer. The commands singularity (now a link pointing to Apptainer) and apptainer may be used to perform all the same operations you're used to and you can still run your existing images. However, remote builds via SyLabs are no longer supported. Instead, in many cases you may build your image directly on a compute node using:
$ singularity build local_image.sif container.recipe
Accessing Apptainer on HPC
Apptainer is installed on the operating systems of all HPC compute nodes, so can be easily accessed either from an interactive session or batch script without worrying about software modules.
Building a Container
With the introduction of Apptainer during the October 26, 2022 maintenance cycle, remote builds on SyLabs are no longer supported. Instead, in most cases it should be possible to build your images directly on a compute node using:
$ apptainer build local_image.sif container.recipe
This has been tested for recipes bootstrapping off of Docker images. We have found that in some cases (e.g. Boostrap: yum images) a local build will fail due to permissions issues. If you experience this and need assistance, contact our consultants and they can help come up with some alternatives.
Apptainer, Nvidia, and GPUs

One of the most significant use cases for Apptainer is to support machine learning workflows. For information on using GPUs on HPC, see our GPU documentation.
Pulling Nvidia Images
The NVIDIA GPU Cloud (NGC) provides GPU-accelerated HPC and deep learning containers for scientific computing. NVIDIA tests HPC container compatibility with the Singularity runtime through a rigorous QA process. Application-specific information may vary so it is recommended that you follow the container-specific documentation before running with Singularity. If the container documentation does not include Singularity information, then the container has not yet been tested under Singularity. Apptainer can be used to pull, execute, and bootstrap off of Singularity images.
Pulling Images Instructions
- The containers from Nvidia that are in /contrib have been modified to include path bindings to /xdisk and /groups. They also include the path to the Nvidia commands like
nvidia-smi. - Because login nodes are small and do not provide software, singularity images should be pulled and executed on a compute node.
To start, you'll need to register with Nvidia. Once you have an account, you can view their images from their catalogue. Click on the name of the software you're interested in to view available versions
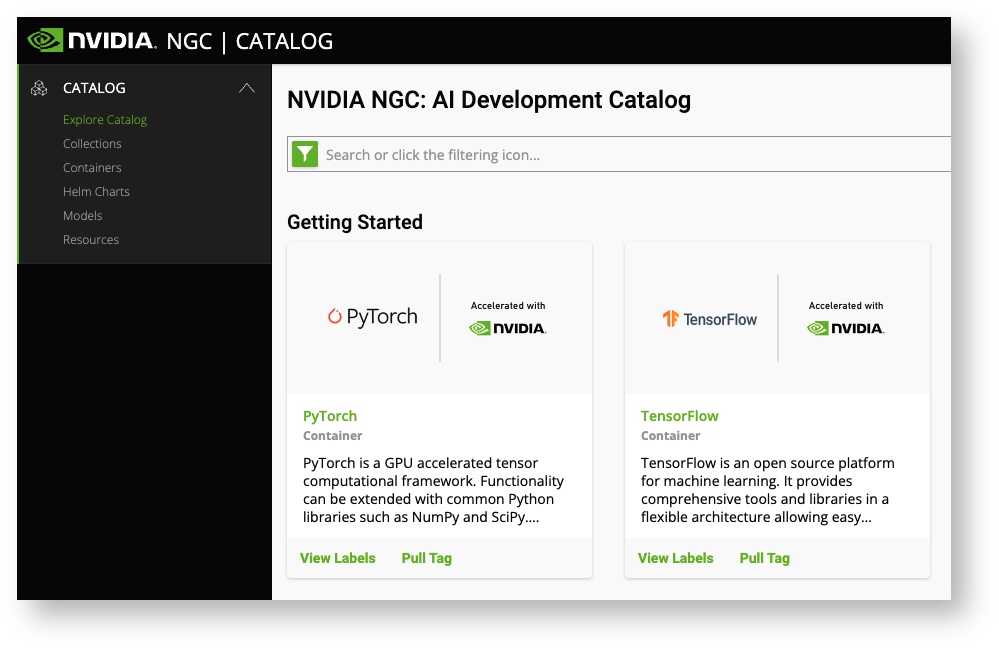
If you click on the Tags tab at the top of the screen, you'll find the different versions that are available for download. For example, if we click on TensorFlow, we can get the pull statement for the latest tag of TensorFlow 2 by clicking the ellipses and selecting Pull Tag.
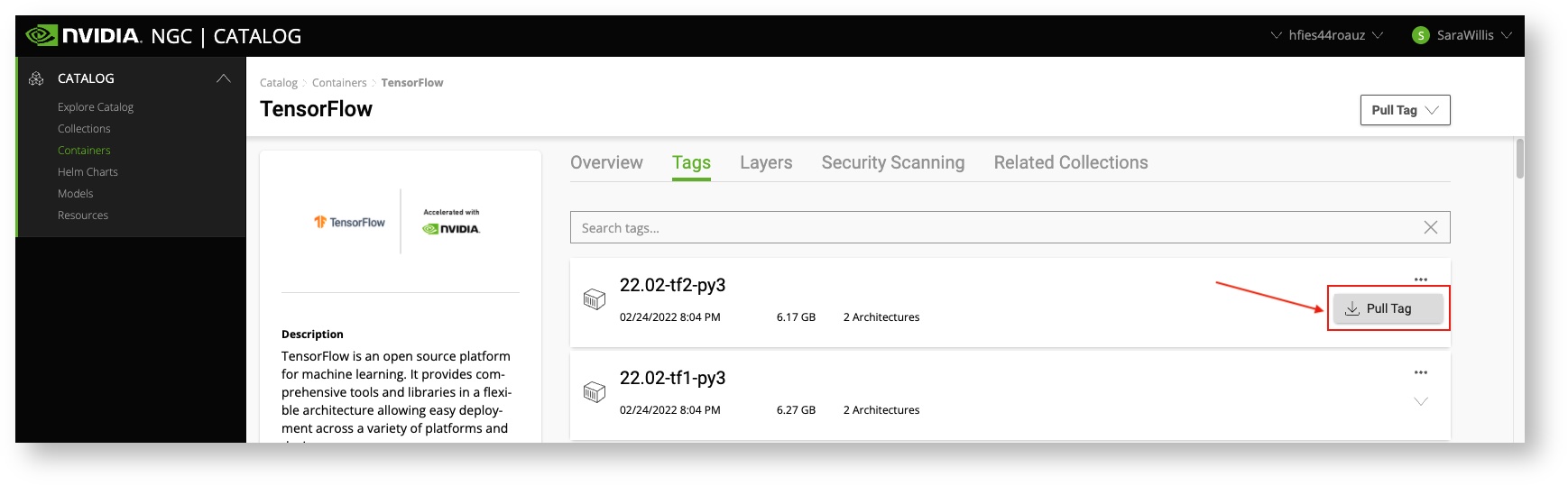
This will copy a docker pull statement to your clipboard, in this case:
$ docker pull nvcr.io/nvidia/tensorflow:22.02-tf2-py3
To pull and convert this NGC image to a local Apptainer image file, we'll convert this to:
$ apptainer build ~/tensorflow2-22.02-py3.sif docker://nvcr.io/nvidia/tensorflow:22.02-tf2-py3
The general format for any pull you want to do is:
$ apptainer build <local_image_name> docker://nvcr.io/<registry>/<app:tag>
This Apptainer build command will download the app:tag NGC Docker image, convert it to Apptainer format, and save it to the local filename local_image_name.
Containers Available on HPC
We support the use of HPC and ML/DL containers available on NVIDIA GPU Cloud (NGC). Many of the popular HPC applications including NAMD, LAMMPS and GROMACS containers are optimized for performance and available to run in Apptainer on Ocelote or Puma. The containers and respective README files can be found in /contrib/singularity/nvidia. But. They are only available from compute nodes, so start an interactive session if you want to view them.
We do not update these very often as it is time consuming and some of them change frequently. So we encourage you to pull your own from Nvidia
- The Nvidia images have been modified to include bindings for your /xdisk and /groups directories if you want to run your jobs there
- The filename has a tag at the end that represents when it was made. For example, 18.01 is January 2018.
| Container | Description |
|---|---|
| nvidia-caffe.20.01-py3.simg | Caffe is a deep learning framework made with expression, speed, and modularity in mind. It was originally developed by the Berkeley Vision and Learning Center (BVLC) |
| nvidia-gromacs.2018.2.simg | |
| nvidia-julia.1.2.0.simg | |
| nvidia-lammps.24Oct2018.sif | |
| nvidia-namd_2.13-multinode.sif | |
| nvidia-pytorch.20.01-py3.simg | PyTorch is a Python package that provides two high-level features:
|
| nvidia-rapidsai.sif | |
| nvidia-relion_2.1.b1.simg | |
| nvidia-tensorflow_2.0.0-py3.sif | TensorFlow is an open source software library for numerical computation using data flow graphs. TensorFlow was originally developed by researchers and engineers working on the Google Brain team within Google's Machine Intelligence research organization for the purposes of conducting machine learning and deep neural networks research. |
| nvidia-theano.18.08.simg | Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. |
Sharing Your Containers
If you have containers that you would like to share with your research group or broader HPC community, you may do so in the space /contrib/singularity/shared. Note that this location is only accessible on a compute node either in an interactive session or batch script.
To do this, start an interactive session and change to /contrib/singularity/shared:
(elgato) [user@junonia ~]$ interactive -a YOUR_GROUP Run "interactive -h for help customizing interactive use" Submitting with /usr/local/bin/salloc --job-name=interactive --mem-per-cpu=4GB --nodes=1 --ntasks=1 --time=01:00:00 --account=YOUR_GROUP --partition=standard salloc: Pending job allocation 308349 salloc: job 308349 queued and waiting for resources salloc: job 308349 has been allocated resources salloc: Granted job allocation 308349 salloc: Waiting for resource configuration salloc: Nodes cpu1 are ready for job [user@cpu1 ~]$ cd /contrib/singularity/shared
Next, create a directory, set the group ownership, and set the permissions. For example, if you wanted your directory to only be writable by you and be accessible to the whole HPC community, you could run (changing user and YOUR_GROUP to match your own desired directory name and HPC group, respectively):
[user@cpu1 shared]$ mkdir user [user@cpu1 shared]$ chgrp YOUR_GROUP user/ [user@cpu1 shared]$ chmod 755 user/ [user@cpu1 shared]$ ls -ld user/ drwxr-sr-x 2 user YOUR_GROUP 0 Apr 11 14:17 user/
Next, add any images you'd like to share to your new directory, for example:
[user@cpu1 shared]$ cd user/ [user@cpu1 user]$ apptainer pull ./hello-world.sif shub://vsoch/hello-world INFO: Downloading shub image 59.8MiB / 59.8MiB [===============================] 100 % 4.8 MiB/s 0s [user@cpu1 user]$ ls hello-world.sif
As soon as your images are in this location, other HPC users can access them interactively or in a batch script. An example batch job is shown below:
#!/bin/bash #SBATCH --job-name=singularity_contrib_example #SBATCH --account=YOUR_GROUP #SBATCH --partition=standard #SBATCH --nodes=1 #SBATCH --ntasks=1 #SBATCH --time=00:01:00 apptainer run /contrib/singularity/shared/user/hello-world.sif
Submitting the job and checking the output:
(elgato) [user@junonia ~]$ sbatch singularity_example.slurm Submitted batch job 308351 (elgato) [user@junonia ~]$ cat slurm-308351.out RaawwWWWWWRRRR!! Avocado!
Tutorials
- The Sylabs GitHub site has files and instructions for creating sample containers.
- Our Github repository has Apptainer examples available that can be run on HPC.
Example Recipe Files
Cache Directory
To speed up image downloads for faster, less redundant builds and pulls, Apptainer sets a cache directory in your home under ~/.apptainer. This directory stores images, metadata, and docker layers that can wind up being reasonably large. If you're struggling with space usage and your home's 50GB quota, one option is to set a new Apptainer cache directory. You can do this by setting the environment variable APPTAINER_CACHEDIR to a new directory. From Apptainer's documentation:
If you change the value of APPTAINER_CACHEDIR be sure to choose a location that is:
Unique to you. Permissions are set on the cache so that private images cached for one user are not exposed to another. This means that APPTAINER_CACHEDIR cannot be shared.
Located on a filesystem with sufficient space for the number and size of container images anticipated.
Located on a filesystem that supports atomic rename, if possible.
For example, if you wanted to set your cache directory to your PI's /groups directory under a directory you own, you could use:
export APPTAINER_CACHEDIR=/groups/pi/netid/.apptainer
Assuming pi is your PI's NetID and netid is your own NetID. To make the change permanent, add this line to the hidden file in your home directory ~/.bashrc